class: title-slide, left, middle # Data Management & Analysis In Research # *A practical approach* ---- <br> .right[ ### Faculty of Family Medicine Workshop ### April 28, 2023 Dr Samuel Blay Nguah .title-t[FWACP FGCPS] ] --- # Workshop outline ---- .pull-left[ ## Data Management - Databases software - Database design & validation - Data verification - Double - Single - Data warehousing - Data migration - Data cleaning ] .pull-left[ ## Data Analysis - Planning your analysis - Text, dummy tables and figures - Software - Data cleaning and missing data - Descriptive statistics - Continuous variables - Categorical variables - Inferential statistics - Hypothesis testing - P-values - Confidence interval - Graphical presentations ] --- # Our study for the day ---- ## Aim - Determine if __New Drug__ has a better BP lowering effect after 2 weeks of administration compared to the __Control Drug__ ## Study type - Randomized Controlled Trial ## Variable to be collected - Age in years - Sex - Initial BP - Final BP --- # Our study for the day ---- ## Study questions - How much does the **New drug** lower the BP? - How much does the **Control drug** lower the BP? - Which of the two drugs **lowers the BP better**? - Is there a difference in the **BP lowering effect** of the two drugs? - Is the **BP lowering effect** related to the **age** of the patient? - Is the **BP lowering effect** related to the **sex** of the patient? --- class: inverse # Our study for the day ---- <img src="Images/hpt_questionnaire.jpg" style="width: 85%" /> --- class: center, middle, inverse # Data Management ---- --- class: center, middle ## Data management software .pull-left[ <img src="Images/redcap_logo.png" style="width: 50%" /> <img src="Images/epidata_logo.gif" style="width: 40%" /> <img src="Images/excel_logo.jpeg" style="width: 40%" /> ] .pull-right[ <img src="Images/microsoft_access_logo.jpg" style="width: 40%" /> <img src="Images/spss_logo.png" style="width: 30%" /> <img src="Images/epiinfo_logo.jpg" style="width: 40%" /> ] --- class: middle, center, inverse <img src="Images/access_interface.jpg" style="width: 110%" /> --- class: middle, center, inverse <img src="Images/epidata_interface.png" style="width: 95%" /> --- # Database design, validation and verification ---- .pull-left[ ## Validation - Limits - Valid ranges - Allowable values - Some software better than others ## Cleaning - Regular review of filled questionnaires - Weekly checking of entered data for correctness ] .pull-right[ ## Verification - **Single entry** - 10% verification - Whole database verification - **Double entry** - Create identical database - Double enter data - Picks data entry errors - Compare the data from both databases - Identify discrepancies - Correct errors as necessary ] --- class: # Data Warehousing, migration & cleaning ---- .pull-left[ ##Warehousing - Backup the data regularly – 3 copies - Backup with versions and dates - Keep in the appropriate format - Microsoft Excel - Text files - PDF - Tiff ## Migration - Moving data around - Should be in stable state ] .pull-right[ - Not all software requires this ##Cleaning - Involves picking out erroneous data - Picks up - Data collection errors - Data entry errors - Strategy depends on - Continuous variable - Discrete variable - Categorical - Etc ] --- class: center, middle, inverse # Data Analysis ---- --- class: center, middle #Data Types <img src="Images/variable_types.jpg" style="width: 100%" /> --- # Variable types ## Independent (predictor) variable - Potentially influences, affects or predicts another variable - E.g: How age influences income make age the independent variable ## Dependent (predicted) variable - Potentially predicted, influenced and affected by another variable - E.g: How age influences income make income the dependent variable --- # Data analysis ## Software - R - Analysis only - Microsoft Excel - Entry and analysis - Stata - Analysis only - SPSS - Entry and analysis --- # Know your data ---- .pull-left[ ## Variables - `id` = Study ID - `treat` = Treatment given - `age` = Age of participant - `sex` = Sex of patient - `bp1` = Initial mean arterial BP - `bp2` = Final mean arterial BP ] .pull-right[ <div id="pnavvimnvk" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#pnavvimnvk table { font-family: serif; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #pnavvimnvk thead, #pnavvimnvk tbody, #pnavvimnvk tfoot, #pnavvimnvk tr, #pnavvimnvk td, #pnavvimnvk th { border-style: none; } #pnavvimnvk p { margin: 0; padding: 0; } #pnavvimnvk .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 20px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 3px; border-top-color: #D5D5D5; border-right-style: solid; border-right-width: 3px; border-right-color: #D5D5D5; border-bottom-style: solid; border-bottom-width: 3px; border-bottom-color: #D5D5D5; border-left-style: solid; border-left-width: 3px; border-left-color: #D5D5D5; } #pnavvimnvk .gt_caption { padding-top: 4px; padding-bottom: 4px; } #pnavvimnvk .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #pnavvimnvk .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #pnavvimnvk .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #pnavvimnvk .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; } #pnavvimnvk .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D5D5D5; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #pnavvimnvk .gt_col_heading { color: #FFFFFF; background-color: #004D80; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #pnavvimnvk .gt_column_spanner_outer { color: #FFFFFF; background-color: #004D80; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #pnavvimnvk .gt_column_spanner_outer:first-child { padding-left: 0; } #pnavvimnvk .gt_column_spanner_outer:last-child { padding-right: 0; } #pnavvimnvk .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #pnavvimnvk .gt_spanner_row { border-bottom-style: hidden; } #pnavvimnvk .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D5D5D5; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #pnavvimnvk .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D5D5D5; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; vertical-align: middle; } #pnavvimnvk .gt_from_md > :first-child { margin-top: 0; } #pnavvimnvk .gt_from_md > :last-child { margin-bottom: 0; } #pnavvimnvk .gt_row { padding-top: 2px; padding-bottom: 2px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D5D5D5; border-left-style: solid; border-left-width: 1px; border-left-color: #D5D5D5; border-right-style: solid; border-right-width: 1px; border-right-color: #D5D5D5; vertical-align: middle; overflow-x: hidden; } #pnavvimnvk .gt_stub { color: #FFFFFF; background-color: #929292; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D5D5D5; padding-left: 5px; padding-right: 5px; } #pnavvimnvk .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #pnavvimnvk .gt_row_group_first td { border-top-width: 2px; } #pnavvimnvk .gt_row_group_first th { border-top-width: 2px; } #pnavvimnvk .gt_summary_row { color: #FFFFFF; background-color: #5F5F5F; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #pnavvimnvk .gt_first_summary_row { border-top-style: solid; border-top-color: #D5D5D5; } #pnavvimnvk .gt_first_summary_row.thick { border-top-width: 2px; } #pnavvimnvk .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; } #pnavvimnvk .gt_grand_summary_row { color: #FFFFFF; background-color: #929292; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #pnavvimnvk .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D5D5D5; } #pnavvimnvk .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D5D5D5; } #pnavvimnvk .gt_striped { background-color: #F4F4F4; } #pnavvimnvk .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D5D5D5; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D5D5D5; } #pnavvimnvk .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #pnavvimnvk .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #pnavvimnvk .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #pnavvimnvk .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #pnavvimnvk .gt_left { text-align: left; } #pnavvimnvk .gt_center { text-align: center; } #pnavvimnvk .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #pnavvimnvk .gt_font_normal { font-weight: normal; } #pnavvimnvk .gt_font_bold { font-weight: bold; } #pnavvimnvk .gt_font_italic { font-style: italic; } #pnavvimnvk .gt_super { font-size: 65%; } #pnavvimnvk .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #pnavvimnvk .gt_asterisk { font-size: 100%; vertical-align: 0; } #pnavvimnvk .gt_indent_1 { text-indent: 5px; } #pnavvimnvk .gt_indent_2 { text-indent: 10px; } #pnavvimnvk .gt_indent_3 { text-indent: 15px; } #pnavvimnvk .gt_indent_4 { text-indent: 20px; } #pnavvimnvk .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="id">id</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col" id="treat">treat</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col" id="age">age</th> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="sex">sex</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col" id="bp1">bp1</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col" id="bp2">bp2</th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="id" class="gt_row gt_left">C1</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">63</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">97.4</td> <td headers="bp2" class="gt_row gt_right">93.1</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C2</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">NA</td> <td headers="sex" class="gt_row gt_left gt_striped">F</td> <td headers="bp1" class="gt_row gt_right gt_striped">97.2</td> <td headers="bp2" class="gt_row gt_right gt_striped">92.4</td></tr> <tr><td headers="id" class="gt_row gt_left">C6</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">62</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">103.4</td> <td headers="bp2" class="gt_row gt_right">99.7</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C7</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">61</td> <td headers="sex" class="gt_row gt_left gt_striped">F</td> <td headers="bp1" class="gt_row gt_right gt_striped">290.1</td> <td headers="bp2" class="gt_row gt_right gt_striped">88.4</td></tr> <tr><td headers="id" class="gt_row gt_left">C9</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">73</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">96.4</td> <td headers="bp2" class="gt_row gt_right">91.1</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C10</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">57</td> <td headers="sex" class="gt_row gt_left gt_striped">F</td> <td headers="bp1" class="gt_row gt_right gt_striped">98.6</td> <td headers="bp2" class="gt_row gt_right gt_striped">90.5</td></tr> <tr><td headers="id" class="gt_row gt_left">C13</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">61</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">97.4</td> <td headers="bp2" class="gt_row gt_right">93.8</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C14</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">999</td> <td headers="sex" class="gt_row gt_left gt_striped">F</td> <td headers="bp1" class="gt_row gt_right gt_striped">97.4</td> <td headers="bp2" class="gt_row gt_right gt_striped">92.6</td></tr> <tr><td headers="id" class="gt_row gt_left">A18</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">51</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">92.2</td> <td headers="bp2" class="gt_row gt_right">86.2</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">A20</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">65</td> <td headers="sex" class="gt_row gt_left gt_striped">F</td> <td headers="bp1" class="gt_row gt_right gt_striped">96.9</td> <td headers="bp2" class="gt_row gt_right gt_striped">90.4</td></tr> <tr><td headers="id" class="gt_row gt_left">A21</td> <td headers="treat" class="gt_row gt_right">NA</td> <td headers="age" class="gt_row gt_right">65</td> <td headers="sex" class="gt_row gt_left">F</td> <td headers="bp1" class="gt_row gt_right">102.6</td> <td headers="bp2" class="gt_row gt_right">91.5</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C3</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">54</td> <td headers="sex" class="gt_row gt_left gt_striped">M</td> <td headers="bp1" class="gt_row gt_right gt_striped">98.8</td> <td headers="bp2" class="gt_row gt_right gt_striped">94.6</td></tr> <tr><td headers="id" class="gt_row gt_left">C4</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">69</td> <td headers="sex" class="gt_row gt_left">M</td> <td headers="bp1" class="gt_row gt_right">98.4</td> <td headers="bp2" class="gt_row gt_right">92.3</td></tr> <tr><td headers="id" class="gt_row gt_left gt_striped">C5</td> <td headers="treat" class="gt_row gt_right gt_striped">0</td> <td headers="age" class="gt_row gt_right gt_striped">75</td> <td headers="sex" class="gt_row gt_left gt_striped">M</td> <td headers="bp1" class="gt_row gt_right gt_striped">89.8</td> <td headers="bp2" class="gt_row gt_right gt_striped">89.3</td></tr> <tr><td headers="id" class="gt_row gt_left">C8</td> <td headers="treat" class="gt_row gt_right">0</td> <td headers="age" class="gt_row gt_right">59</td> <td headers="sex" class="gt_row gt_left">M</td> <td headers="bp1" class="gt_row gt_right">93.7</td> <td headers="bp2" class="gt_row gt_right">90.4</td></tr> </tbody> </table> </div> ] --- # Summarizing data .center[ ``` id treat age sex Length:50 Min. :0.0000 Min. : 45.00 Length:50 Class :character 1st Qu.:0.0000 1st Qu.: 57.75 Class :character Mode :character Median :1.0000 Median : 63.00 Mode :character Mean :0.5714 Mean : 81.00 3rd Qu.:1.0000 3rd Qu.: 65.00 Max. :1.0000 Max. :999.00 NA's :1 NA's :2 bp1 bp2 Min. : 87.5 Min. :78.00 1st Qu.: 96.0 1st Qu.:85.20 Median : 98.0 Median :88.40 Mean :102.4 Mean :88.61 3rd Qu.:101.2 3rd Qu.:92.30 Max. :290.1 Max. :99.70 NA's :1 NA's :1 ``` ] --- # Pre-processing of data ---- .pull-left[ ## Data cleaning - Involves picking out erroneous data - Picks up - Data collection errors - Data entry errors - Strategy depends on - Continuous variable OR Discrete variable ] .pull-right[ # Steps (personal) - Check study id - Any duplication in whole data? - Any duplication in study id? - Any missing study id? - Sort them out if possible - General overview of data - single categorical variables - Single continuous variables - Combination of variables – Categorical - Combination of variables - Continuous ] --- # Pre-processing of data ---- ## Missing data - Know the pattern - Know how to deal with them - Dropping observations - Imputation - Commonest observation - Median/Mean - MICE --- # Missing pattern <!-- --> --- # Pre-processing of data ---- ## Generating new variables 1. Convert data to appropriate types - `sex` to categorical variable (factor) - `treat` to categorical variable 1. Fill missing data with appropriate data 1. Correct abnormal values in BPs 1. Generate variable(s) - `bp_diff` = Difference in BP - `age_group`: - Elderly: >60 years - Middle age: <=60 years --- # Data summary after cleaning .center[ ``` id treat age sex bp1 Length:50 Old Drug:22 Min. :45.00 Female:26 Min. : 87.50 Class :character New Drug:28 1st Qu.:57.25 Male :24 1st Qu.: 95.62 Mode :character Median :63.00 Median : 97.70 Mean :61.48 Mean : 98.30 3rd Qu.:65.00 3rd Qu.: 99.40 Max. :75.00 Max. :111.70 bp2 bp_diff age_group Min. :78.00 Min. : 0.500 Middle age:17 1st Qu.:85.22 1st Qu.: 4.800 Elderly :33 Median :88.15 Median : 8.250 Mean :88.60 Mean : 9.704 3rd Qu.:92.10 3rd Qu.:13.700 Max. :99.70 Max. :26.300 ``` ] --- # Descriptive statistics ---- .pull-left[ # Categorical variable - Frequency tables – univariate - Contingency tables – bivariate - Row percentage - Column percentage - Graphical representations - Bar chart - Pie Chart - Others - Odds & Odds Ratio - Risk & Risk Ratio ] .pull-right[ ## Continuous Variable - Measures of central tendency - Mean - Arithmetic Mean - Geometric mean - Harmonic mean - Median - Mode - Measures of dispersion - Standard deviation - Variance - Interquartile range - Range ] --- # Categorical variables ---- .pull-left[ ##Univariate analysis <div id="hwmmyhgjyf" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#hwmmyhgjyf table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #hwmmyhgjyf thead, #hwmmyhgjyf tbody, #hwmmyhgjyf tfoot, #hwmmyhgjyf tr, #hwmmyhgjyf td, #hwmmyhgjyf th { border-style: none; } #hwmmyhgjyf p { margin: 0; padding: 0; } #hwmmyhgjyf .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #hwmmyhgjyf .gt_caption { padding-top: 4px; padding-bottom: 4px; } #hwmmyhgjyf .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #hwmmyhgjyf .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #hwmmyhgjyf .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #hwmmyhgjyf .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hwmmyhgjyf .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #hwmmyhgjyf .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #hwmmyhgjyf .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #hwmmyhgjyf .gt_column_spanner_outer:first-child { padding-left: 0; } #hwmmyhgjyf .gt_column_spanner_outer:last-child { padding-right: 0; } #hwmmyhgjyf .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #hwmmyhgjyf .gt_spanner_row { border-bottom-style: hidden; } #hwmmyhgjyf .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #hwmmyhgjyf .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #hwmmyhgjyf .gt_from_md > :first-child { margin-top: 0; } #hwmmyhgjyf .gt_from_md > :last-child { margin-bottom: 0; } #hwmmyhgjyf .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #hwmmyhgjyf .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #hwmmyhgjyf .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #hwmmyhgjyf .gt_row_group_first td { border-top-width: 2px; } #hwmmyhgjyf .gt_row_group_first th { border-top-width: 2px; } #hwmmyhgjyf .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #hwmmyhgjyf .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #hwmmyhgjyf .gt_first_summary_row.thick { border-top-width: 2px; } #hwmmyhgjyf .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hwmmyhgjyf .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #hwmmyhgjyf .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #hwmmyhgjyf .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #hwmmyhgjyf .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #hwmmyhgjyf .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hwmmyhgjyf .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #hwmmyhgjyf .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #hwmmyhgjyf .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #hwmmyhgjyf .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #hwmmyhgjyf .gt_left { text-align: left; } #hwmmyhgjyf .gt_center { text-align: center; } #hwmmyhgjyf .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #hwmmyhgjyf .gt_font_normal { font-weight: normal; } #hwmmyhgjyf .gt_font_bold { font-weight: bold; } #hwmmyhgjyf .gt_font_italic { font-style: italic; } #hwmmyhgjyf .gt_super { font-size: 65%; } #hwmmyhgjyf .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #hwmmyhgjyf .gt_asterisk { font-size: 100%; vertical-align: 0; } #hwmmyhgjyf .gt_indent_1 { text-indent: 5px; } #hwmmyhgjyf .gt_indent_2 { text-indent: 10px; } #hwmmyhgjyf .gt_indent_3 { text-indent: 15px; } #hwmmyhgjyf .gt_indent_4 { text-indent: 20px; } #hwmmyhgjyf .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 1</strong>: Univariate categorical table</caption> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>N = 50</strong>"><strong>N = 50</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Treatment Type, n (%)</td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Old Drug</td> <td headers="stat_0" class="gt_row gt_center">22 (44.0)</td></tr> <tr><td headers="label" class="gt_row gt_left"> New Drug</td> <td headers="stat_0" class="gt_row gt_center">28 (56.0)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Sex, n (%)</td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Female</td> <td headers="stat_0" class="gt_row gt_center">26 (52.0)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Male</td> <td headers="stat_0" class="gt_row gt_center">24 (48.0)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Age Grouping, n (%)</td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Middle age</td> <td headers="stat_0" class="gt_row gt_center">17 (34.0)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Elderly</td> <td headers="stat_0" class="gt_row gt_center">33 (66.0)</td></tr> </tbody> </table> </div> ] .pull-right[ ## Bivariate analysis <div id="xdhkwvelhj" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#xdhkwvelhj table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #xdhkwvelhj thead, #xdhkwvelhj tbody, #xdhkwvelhj tfoot, #xdhkwvelhj tr, #xdhkwvelhj td, #xdhkwvelhj th { border-style: none; } #xdhkwvelhj p { margin: 0; padding: 0; } #xdhkwvelhj .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #xdhkwvelhj .gt_caption { padding-top: 4px; padding-bottom: 4px; } #xdhkwvelhj .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #xdhkwvelhj .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #xdhkwvelhj .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xdhkwvelhj .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xdhkwvelhj .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xdhkwvelhj .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #xdhkwvelhj .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #xdhkwvelhj .gt_column_spanner_outer:first-child { padding-left: 0; } #xdhkwvelhj .gt_column_spanner_outer:last-child { padding-right: 0; } #xdhkwvelhj .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #xdhkwvelhj .gt_spanner_row { border-bottom-style: hidden; } #xdhkwvelhj .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #xdhkwvelhj .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #xdhkwvelhj .gt_from_md > :first-child { margin-top: 0; } #xdhkwvelhj .gt_from_md > :last-child { margin-bottom: 0; } #xdhkwvelhj .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #xdhkwvelhj .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #xdhkwvelhj .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #xdhkwvelhj .gt_row_group_first td { border-top-width: 2px; } #xdhkwvelhj .gt_row_group_first th { border-top-width: 2px; } #xdhkwvelhj .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xdhkwvelhj .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #xdhkwvelhj .gt_first_summary_row.thick { border-top-width: 2px; } #xdhkwvelhj .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xdhkwvelhj .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xdhkwvelhj .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #xdhkwvelhj .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #xdhkwvelhj .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #xdhkwvelhj .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xdhkwvelhj .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xdhkwvelhj .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #xdhkwvelhj .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xdhkwvelhj .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #xdhkwvelhj .gt_left { text-align: left; } #xdhkwvelhj .gt_center { text-align: center; } #xdhkwvelhj .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #xdhkwvelhj .gt_font_normal { font-weight: normal; } #xdhkwvelhj .gt_font_bold { font-weight: bold; } #xdhkwvelhj .gt_font_italic { font-style: italic; } #xdhkwvelhj .gt_super { font-size: 65%; } #xdhkwvelhj .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #xdhkwvelhj .gt_asterisk { font-size: 100%; vertical-align: 0; } #xdhkwvelhj .gt_indent_1 { text-indent: 5px; } #xdhkwvelhj .gt_indent_2 { text-indent: 10px; } #xdhkwvelhj .gt_indent_3 { text-indent: 15px; } #xdhkwvelhj .gt_indent_4 { text-indent: 20px; } #xdhkwvelhj .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 2</strong>: Bivariate categorical table</caption> <thead> <tr class="gt_col_headings gt_spanner_row"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="2" colspan="1" scope="col" id=""></th> <th class="gt_center gt_columns_top_border gt_column_spanner_outer" rowspan="1" colspan="2" scope="colgroup" id="<strong>Treatment Type</strong>"> <span class="gt_column_spanner"><strong>Treatment Type</strong></span> </th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="2" colspan="1" scope="col" id="<strong>Total</strong>"><strong>Total</strong></th> </tr> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<em>Old Drug</em>"><em>Old Drug</em></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<em>New Drug</em>"><em>New Drug</em></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Sex</td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Female</td> <td headers="stat_1" class="gt_row gt_center">11 (42%)</td> <td headers="stat_2" class="gt_row gt_center">15 (58%)</td> <td headers="stat_0" class="gt_row gt_center">26 (100%)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Male</td> <td headers="stat_1" class="gt_row gt_center">11 (46%)</td> <td headers="stat_2" class="gt_row gt_center">13 (54%)</td> <td headers="stat_0" class="gt_row gt_center">24 (100%)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Total</td> <td headers="stat_1" class="gt_row gt_center">22 (44%)</td> <td headers="stat_2" class="gt_row gt_center">28 (56%)</td> <td headers="stat_0" class="gt_row gt_center">50 (100%)</td></tr> </tbody> </table> </div> ] --- # Categorical variables ---- ##Bivariate tables <div id="hgapffxues" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#hgapffxues table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #hgapffxues thead, #hgapffxues tbody, #hgapffxues tfoot, #hgapffxues tr, #hgapffxues td, #hgapffxues th { border-style: none; } #hgapffxues p { margin: 0; padding: 0; } #hgapffxues .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #hgapffxues .gt_caption { padding-top: 4px; padding-bottom: 4px; } #hgapffxues .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #hgapffxues .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #hgapffxues .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #hgapffxues .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hgapffxues .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #hgapffxues .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #hgapffxues .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #hgapffxues .gt_column_spanner_outer:first-child { padding-left: 0; } #hgapffxues .gt_column_spanner_outer:last-child { padding-right: 0; } #hgapffxues .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #hgapffxues .gt_spanner_row { border-bottom-style: hidden; } #hgapffxues .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #hgapffxues .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #hgapffxues .gt_from_md > :first-child { margin-top: 0; } #hgapffxues .gt_from_md > :last-child { margin-bottom: 0; } #hgapffxues .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #hgapffxues .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #hgapffxues .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #hgapffxues .gt_row_group_first td { border-top-width: 2px; } #hgapffxues .gt_row_group_first th { border-top-width: 2px; } #hgapffxues .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #hgapffxues .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #hgapffxues .gt_first_summary_row.thick { border-top-width: 2px; } #hgapffxues .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hgapffxues .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #hgapffxues .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #hgapffxues .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #hgapffxues .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #hgapffxues .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #hgapffxues .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #hgapffxues .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #hgapffxues .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #hgapffxues .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #hgapffxues .gt_left { text-align: left; } #hgapffxues .gt_center { text-align: center; } #hgapffxues .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #hgapffxues .gt_font_normal { font-weight: normal; } #hgapffxues .gt_font_bold { font-weight: bold; } #hgapffxues .gt_font_italic { font-style: italic; } #hgapffxues .gt_super { font-size: 65%; } #hgapffxues .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #hgapffxues .gt_asterisk { font-size: 100%; vertical-align: 0; } #hgapffxues .gt_indent_1 { text-indent: 5px; } #hgapffxues .gt_indent_2 { text-indent: 10px; } #hgapffxues .gt_indent_3 { text-indent: 15px; } #hgapffxues .gt_indent_4 { text-indent: 20px; } #hgapffxues .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 3</strong>: Bivariate categorical table</caption> <thead> <tr class="gt_col_headings gt_spanner_row"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="2" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="2" colspan="1" scope="col" id="<strong>Overall</strong>, N = 50<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>Overall</strong>, N = 50<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_center gt_columns_top_border gt_column_spanner_outer" rowspan="1" colspan="2" scope="colgroup" id="<strong>Treatment given</strong>"> <span class="gt_column_spanner"><strong>Treatment given</strong></span> </th> </tr> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Old Drug</strong>, N = 22"><strong>Old Drug</strong>, N = 22</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>New Drug</strong>, N = 28"><strong>New Drug</strong>, N = 28</th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Sex, n (%)</td> <td headers="stat_0" class="gt_row gt_center"></td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Female</td> <td headers="stat_0" class="gt_row gt_center">26 (52.0)</td> <td headers="stat_1" class="gt_row gt_center">11 (50.0)</td> <td headers="stat_2" class="gt_row gt_center">15 (53.6)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Male</td> <td headers="stat_0" class="gt_row gt_center">24 (48.0)</td> <td headers="stat_1" class="gt_row gt_center">11 (50.0)</td> <td headers="stat_2" class="gt_row gt_center">13 (46.4)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Age Grouping, n (%)</td> <td headers="stat_0" class="gt_row gt_center"></td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Middle age</td> <td headers="stat_0" class="gt_row gt_center">17 (34.0)</td> <td headers="stat_1" class="gt_row gt_center">7 (31.8)</td> <td headers="stat_2" class="gt_row gt_center">10 (35.7)</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-style: italic;"> Elderly</td> <td headers="stat_0" class="gt_row gt_center">33 (66.0)</td> <td headers="stat_1" class="gt_row gt_center">15 (68.2)</td> <td headers="stat_2" class="gt_row gt_center">18 (64.3)</td></tr> </tbody> <tfoot class="gt_footnotes"> <tr> <td class="gt_footnote" colspan="4"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span> n (%)</td> </tr> </tfoot> </table> </div> --- # Categorical variables plots ---- .pull-left[ **Pie Chart** <br> <!-- --> ] .pull-right[ **Bar Chart - Univariate** <br> <!-- --> ] --- # Categorical variables plots ---- **Barchart - Bivariate** .pull-left[ <!-- --> ] .pull-right[ 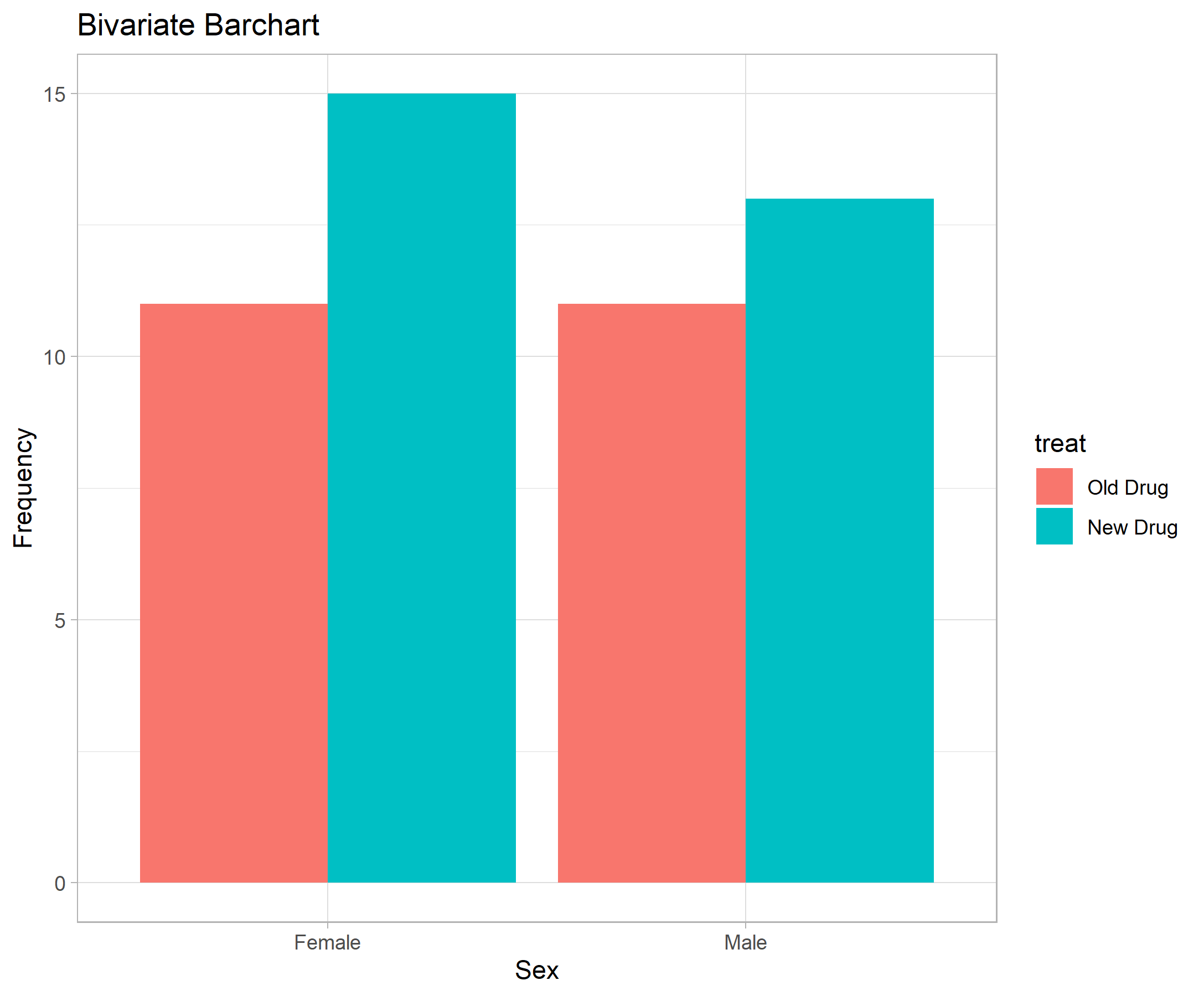<!-- --> ] --- # Measures of Asociation ---- .pull-left[ ## Risk - Risk (probability, likelihood) - Probability of outcome in a specified period - If 200 children in a boarding school ate rice and 28 had diarrhea then $$ R_𝑒 = \frac{28}{200} = 0.14 = 14\% $$ ] .pull-right[ ## Odds $$ = \frac{Risk\ of\ getting\ the\ disease}{(Risk\ of\ not\ getting\ the\ disease)} $$ $$ Odds_e = \frac{0.14}{1-0.14} = \frac{0.14}{0.86} \approx 0.16$$ ] --- # Measures of association ---- ## Risk Ratio (RR) `$$= \frac{Incidence\ in\ the\ exposed}{Incidence\ in\ the\ non-exposed} = \frac{R_e}{𝑅_𝑢}$$` - Used for estimation of causal relationship - Can be calculated in cohort studies - Higher RR => Better causal relationship - RR=1 => No evidence of association - RR `\(\neq\)` 1 => Exposure is harmful or protective --- # Measures of association ---- ## Odds Ratio (OR) `$$= \frac{Odds\ in\ the\ exposed}{Odds\ in\ the\ non-exposed} = \frac{Odds_e}{Odds_𝑢}$$` - Used for estimation of causal relationship - Can be calculated in case-control studies - Higher RR => Better causal relationship - OR=1 => No evidence of association - OR `\(\neq\)` 1 => Exposure is harmful or protective --- # Descriptive statistics ---- .pull-left[ ## Measures of central tendency - Mean - Median - Mode ] .pull-right[ ##Measure of Dispersion - Range – Minimum to maximum - Interquartile range - p25 - p75 - Quartiles - Minimum, p25, p75, maximum - Standard Deviation - Variance ] --- #Descriptive Statistics ---- .pull-left[ <div id="ortwwxxaks" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#ortwwxxaks table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #ortwwxxaks thead, #ortwwxxaks tbody, #ortwwxxaks tfoot, #ortwwxxaks tr, #ortwwxxaks td, #ortwwxxaks th { border-style: none; } #ortwwxxaks p { margin: 0; padding: 0; } #ortwwxxaks .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #ortwwxxaks .gt_caption { padding-top: 4px; padding-bottom: 4px; } #ortwwxxaks .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #ortwwxxaks .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #ortwwxxaks .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #ortwwxxaks .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #ortwwxxaks .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #ortwwxxaks .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #ortwwxxaks .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #ortwwxxaks .gt_column_spanner_outer:first-child { padding-left: 0; } #ortwwxxaks .gt_column_spanner_outer:last-child { padding-right: 0; } #ortwwxxaks .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #ortwwxxaks .gt_spanner_row { border-bottom-style: hidden; } #ortwwxxaks .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #ortwwxxaks .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #ortwwxxaks .gt_from_md > :first-child { margin-top: 0; } #ortwwxxaks .gt_from_md > :last-child { margin-bottom: 0; } #ortwwxxaks .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #ortwwxxaks .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #ortwwxxaks .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #ortwwxxaks .gt_row_group_first td { border-top-width: 2px; } #ortwwxxaks .gt_row_group_first th { border-top-width: 2px; } #ortwwxxaks .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #ortwwxxaks .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #ortwwxxaks .gt_first_summary_row.thick { border-top-width: 2px; } #ortwwxxaks .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #ortwwxxaks .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #ortwwxxaks .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #ortwwxxaks .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #ortwwxxaks .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #ortwwxxaks .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #ortwwxxaks .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #ortwwxxaks .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #ortwwxxaks .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #ortwwxxaks .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #ortwwxxaks .gt_left { text-align: left; } #ortwwxxaks .gt_center { text-align: center; } #ortwwxxaks .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #ortwwxxaks .gt_font_normal { font-weight: normal; } #ortwwxxaks .gt_font_bold { font-weight: bold; } #ortwwxxaks .gt_font_italic { font-style: italic; } #ortwwxxaks .gt_super { font-size: 65%; } #ortwwxxaks .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #ortwwxxaks .gt_asterisk { font-size: 100%; vertical-align: 0; } #ortwwxxaks .gt_indent_1 { text-indent: 5px; } #ortwwxxaks .gt_indent_2 { text-indent: 10px; } #ortwwxxaks .gt_indent_3 { text-indent: 15px; } #ortwwxxaks .gt_indent_4 { text-indent: 20px; } #ortwwxxaks .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 4</strong>: Univariate descriptive statistics</caption> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>N = 50</strong>"><strong>N = 50</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Initial blood pressure (mmHg)</td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Median (IQR)</td> <td headers="stat_0" class="gt_row gt_center">97.7 (95.6, 99.4)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Mean (SD)</td> <td headers="stat_0" class="gt_row gt_center">98.3 (5.2)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Range</td> <td headers="stat_0" class="gt_row gt_center">87.5, 111.7</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Blood Pressure after treatment</td> <td headers="stat_0" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Median (IQR)</td> <td headers="stat_0" class="gt_row gt_center">88.2 (85.2, 92.1)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Mean (SD)</td> <td headers="stat_0" class="gt_row gt_center">88.6 (4.6)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Range</td> <td headers="stat_0" class="gt_row gt_center">78.0, 99.7</td></tr> </tbody> </table> </div> ] .pull-right[ <div id="keqdcvqosi" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#keqdcvqosi table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #keqdcvqosi thead, #keqdcvqosi tbody, #keqdcvqosi tfoot, #keqdcvqosi tr, #keqdcvqosi td, #keqdcvqosi th { border-style: none; } #keqdcvqosi p { margin: 0; padding: 0; } #keqdcvqosi .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #keqdcvqosi .gt_caption { padding-top: 4px; padding-bottom: 4px; } #keqdcvqosi .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #keqdcvqosi .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #keqdcvqosi .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #keqdcvqosi .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #keqdcvqosi .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #keqdcvqosi .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #keqdcvqosi .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #keqdcvqosi .gt_column_spanner_outer:first-child { padding-left: 0; } #keqdcvqosi .gt_column_spanner_outer:last-child { padding-right: 0; } #keqdcvqosi .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #keqdcvqosi .gt_spanner_row { border-bottom-style: hidden; } #keqdcvqosi .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #keqdcvqosi .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #keqdcvqosi .gt_from_md > :first-child { margin-top: 0; } #keqdcvqosi .gt_from_md > :last-child { margin-bottom: 0; } #keqdcvqosi .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #keqdcvqosi .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #keqdcvqosi .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #keqdcvqosi .gt_row_group_first td { border-top-width: 2px; } #keqdcvqosi .gt_row_group_first th { border-top-width: 2px; } #keqdcvqosi .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #keqdcvqosi .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #keqdcvqosi .gt_first_summary_row.thick { border-top-width: 2px; } #keqdcvqosi .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #keqdcvqosi .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #keqdcvqosi .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #keqdcvqosi .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #keqdcvqosi .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #keqdcvqosi .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #keqdcvqosi .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #keqdcvqosi .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #keqdcvqosi .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #keqdcvqosi .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #keqdcvqosi .gt_left { text-align: left; } #keqdcvqosi .gt_center { text-align: center; } #keqdcvqosi .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #keqdcvqosi .gt_font_normal { font-weight: normal; } #keqdcvqosi .gt_font_bold { font-weight: bold; } #keqdcvqosi .gt_font_italic { font-style: italic; } #keqdcvqosi .gt_super { font-size: 65%; } #keqdcvqosi .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #keqdcvqosi .gt_asterisk { font-size: 100%; vertical-align: 0; } #keqdcvqosi .gt_indent_1 { text-indent: 5px; } #keqdcvqosi .gt_indent_2 { text-indent: 10px; } #keqdcvqosi .gt_indent_3 { text-indent: 15px; } #keqdcvqosi .gt_indent_4 { text-indent: 20px; } #keqdcvqosi .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 5</strong>: Bivariate descriptive statistics</caption> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Old Drug</strong>, N = 22"><strong>Old Drug</strong>, N = 22</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>New Drug</strong>, N = 28"><strong>New Drug</strong>, N = 28</th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Initial blood pressure (mmHg)</td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Median (IQR)</td> <td headers="stat_1" class="gt_row gt_center">97.4 (95.5, 98.8)</td> <td headers="stat_2" class="gt_row gt_center">98.3 (95.9, 101.7)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Mean (SD)</td> <td headers="stat_1" class="gt_row gt_center">97.1 (3.6)</td> <td headers="stat_2" class="gt_row gt_center">99.2 (6.0)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Range</td> <td headers="stat_1" class="gt_row gt_center">89.8, 103.4</td> <td headers="stat_2" class="gt_row gt_center">87.5, 111.7</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Blood Pressure after treatment</td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Median (IQR)</td> <td headers="stat_1" class="gt_row gt_center">91.9 (90.4, 93.6)</td> <td headers="stat_2" class="gt_row gt_center">85.4 (84.4, 87.2)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Mean (SD)</td> <td headers="stat_1" class="gt_row gt_center">92.2 (3.3)</td> <td headers="stat_2" class="gt_row gt_center">85.8 (3.3)</td></tr> <tr><td headers="label" class="gt_row gt_left"> Range</td> <td headers="stat_1" class="gt_row gt_center">86.2, 99.7</td> <td headers="stat_2" class="gt_row gt_center">78.0, 94.2</td></tr> </tbody> </table> </div> ] --- # Descriptive Statistics ---- .pull-left[ ## Histogram 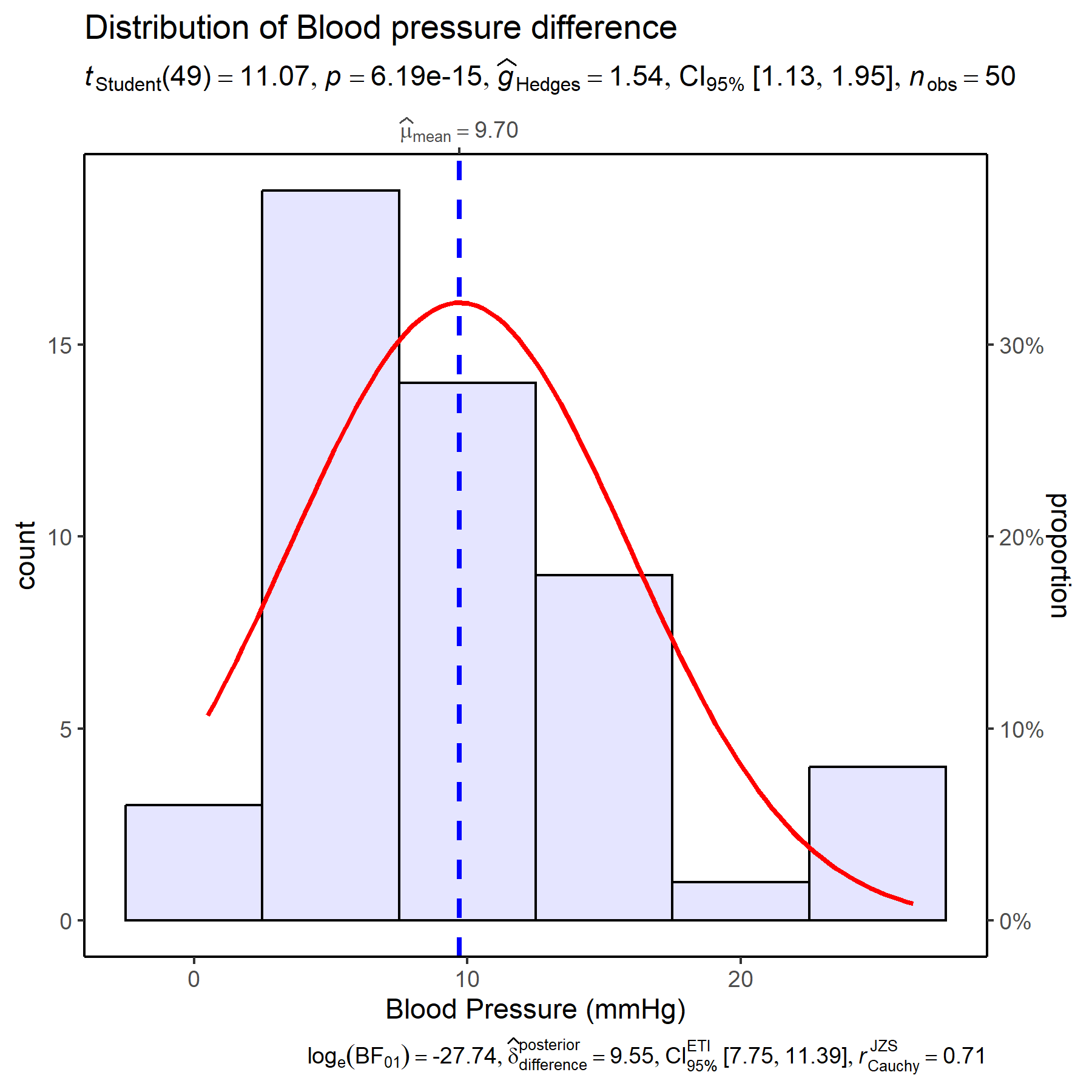<!-- --> ] .pull-right[ ## Boxplot <!-- --> ] --- #Descriptive Statistics - plots .pull-left[ ## Scatter plot <!-- --> ] .pull-right[ ##Boxplot <!-- --> ] --- class: inverse middle center # Inferential statistics ---- --- class: center, middle #Sample vrs. Population <img src="Images/sample-population.png" style="width: 100%" /> --- class: center, middle #Statistic vrs. Parameter <img src="Images/statistic-parameter.png" style="width: 100%" /> --- class: center, middle #Sample variation <img src="Images/sample-variation.png" style="width: 100%" /> --- #Estimates ---- - Point estimates - Interval estimates .red[**Confidence interval**] .red[**The 95% confidence interval is the interval that is likely to contain the population parameter 95% of the time.**] --- class: center, middle #95% Confidence interval <img src="Images/interval-estimate-95.png" style="width: 100%" /> --- # p-value ---- - Well known in research - Very often misinterpreted and overemphasized > .red[**It is the probability of having a statistic as extreme as the one observed from the sample if the null hypothesis is true. It determines the strength of support for the null hypothesis.**] - The nearer p-value is to 1 the better the data at hand or test statistic supports the null value. --- #Hypothesis testing ---- 1. State (Null) hypothesis (H0) 1. Decide on significance level (α) usually 0.05 1. Determine sample size 1. Collect data (Evidence) 1. Apply appropriate statistical test 1. Compute the probability value (p-value) 1. We compare the p-value with α 1. If p < α Then: Reject the H0 (Guilty) 1. If p >= α Then: Refuse to reject the H0 (Not guilty) Generally: - Lower p-value: More confident of rejecting the H0 - Note that failure to reject H0 does not mean H0 is true. It means we do not have enough evidence to reject it --- class: middle, center, inverse # Statistical Tests <img src="Images/statistical_tests.jpg" style="width: 90%" /> --- class: inverse middle center # Answering our questions from our study --- # How much does the New drug lower the BP? # How much does the Control drug lower the BP? # Which of the two drugs lowers the BP better? ---- <div id="yvtnyhsgrx" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#yvtnyhsgrx table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #yvtnyhsgrx thead, #yvtnyhsgrx tbody, #yvtnyhsgrx tfoot, #yvtnyhsgrx tr, #yvtnyhsgrx td, #yvtnyhsgrx th { border-style: none; } #yvtnyhsgrx p { margin: 0; padding: 0; } #yvtnyhsgrx .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #yvtnyhsgrx .gt_caption { padding-top: 4px; padding-bottom: 4px; } #yvtnyhsgrx .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #yvtnyhsgrx .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #yvtnyhsgrx .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #yvtnyhsgrx .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #yvtnyhsgrx .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #yvtnyhsgrx .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #yvtnyhsgrx .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #yvtnyhsgrx .gt_column_spanner_outer:first-child { padding-left: 0; } #yvtnyhsgrx .gt_column_spanner_outer:last-child { padding-right: 0; } #yvtnyhsgrx .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #yvtnyhsgrx .gt_spanner_row { border-bottom-style: hidden; } #yvtnyhsgrx .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #yvtnyhsgrx .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #yvtnyhsgrx .gt_from_md > :first-child { margin-top: 0; } #yvtnyhsgrx .gt_from_md > :last-child { margin-bottom: 0; } #yvtnyhsgrx .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #yvtnyhsgrx .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #yvtnyhsgrx .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #yvtnyhsgrx .gt_row_group_first td { border-top-width: 2px; } #yvtnyhsgrx .gt_row_group_first th { border-top-width: 2px; } #yvtnyhsgrx .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #yvtnyhsgrx .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #yvtnyhsgrx .gt_first_summary_row.thick { border-top-width: 2px; } #yvtnyhsgrx .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #yvtnyhsgrx .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #yvtnyhsgrx .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #yvtnyhsgrx .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #yvtnyhsgrx .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #yvtnyhsgrx .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #yvtnyhsgrx .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #yvtnyhsgrx .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #yvtnyhsgrx .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #yvtnyhsgrx .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #yvtnyhsgrx .gt_left { text-align: left; } #yvtnyhsgrx .gt_center { text-align: center; } #yvtnyhsgrx .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #yvtnyhsgrx .gt_font_normal { font-weight: normal; } #yvtnyhsgrx .gt_font_bold { font-weight: bold; } #yvtnyhsgrx .gt_font_italic { font-style: italic; } #yvtnyhsgrx .gt_super { font-size: 65%; } #yvtnyhsgrx .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #yvtnyhsgrx .gt_asterisk { font-size: 100%; vertical-align: 0; } #yvtnyhsgrx .gt_indent_1 { text-indent: 5px; } #yvtnyhsgrx .gt_indent_2 { text-indent: 10px; } #yvtnyhsgrx .gt_indent_3 { text-indent: 15px; } #yvtnyhsgrx .gt_indent_4 { text-indent: 20px; } #yvtnyhsgrx .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span>"><strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span>"><strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left">Change in Blood Pressure</td> <td headers="stat_1" class="gt_row gt_center">4.9 (2.3)</td> <td headers="ci_stat_1" class="gt_row gt_center">3.9, 5.9</td> <td headers="stat_2" class="gt_row gt_center">13.4 (5.7)</td> <td headers="ci_stat_2" class="gt_row gt_center">11, 16</td></tr> </tbody> <tfoot class="gt_footnotes"> <tr> <td class="gt_footnote" colspan="5"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span> Mean (SD)</td> </tr> <tr> <td class="gt_footnote" colspan="5"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span> CI = Confidence Interval</td> </tr> </tfoot> </table> </div> --- # Is there a difference in the BP lowering effect of the two drugs? **H0**: No difference in BP lowering effect between the two drugs <div id="cqblybheoa" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#cqblybheoa table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #cqblybheoa thead, #cqblybheoa tbody, #cqblybheoa tfoot, #cqblybheoa tr, #cqblybheoa td, #cqblybheoa th { border-style: none; } #cqblybheoa p { margin: 0; padding: 0; } #cqblybheoa .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #cqblybheoa .gt_caption { padding-top: 4px; padding-bottom: 4px; } #cqblybheoa .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #cqblybheoa .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #cqblybheoa .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #cqblybheoa .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #cqblybheoa .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #cqblybheoa .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #cqblybheoa .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #cqblybheoa .gt_column_spanner_outer:first-child { padding-left: 0; } #cqblybheoa .gt_column_spanner_outer:last-child { padding-right: 0; } #cqblybheoa .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #cqblybheoa .gt_spanner_row { border-bottom-style: hidden; } #cqblybheoa .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #cqblybheoa .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #cqblybheoa .gt_from_md > :first-child { margin-top: 0; } #cqblybheoa .gt_from_md > :last-child { margin-bottom: 0; } #cqblybheoa .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #cqblybheoa .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #cqblybheoa .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #cqblybheoa .gt_row_group_first td { border-top-width: 2px; } #cqblybheoa .gt_row_group_first th { border-top-width: 2px; } #cqblybheoa .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #cqblybheoa .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #cqblybheoa .gt_first_summary_row.thick { border-top-width: 2px; } #cqblybheoa .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #cqblybheoa .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #cqblybheoa .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #cqblybheoa .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #cqblybheoa .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #cqblybheoa .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #cqblybheoa .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #cqblybheoa .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #cqblybheoa .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #cqblybheoa .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #cqblybheoa .gt_left { text-align: left; } #cqblybheoa .gt_center { text-align: center; } #cqblybheoa .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #cqblybheoa .gt_font_normal { font-weight: normal; } #cqblybheoa .gt_font_bold { font-weight: bold; } #cqblybheoa .gt_font_italic { font-style: italic; } #cqblybheoa .gt_super { font-size: 65%; } #cqblybheoa .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #cqblybheoa .gt_asterisk { font-size: 100%; vertical-align: 0; } #cqblybheoa .gt_indent_1 { text-indent: 5px; } #cqblybheoa .gt_indent_2 { text-indent: 10px; } #cqblybheoa .gt_indent_3 { text-indent: 15px; } #cqblybheoa .gt_indent_4 { text-indent: 20px; } #cqblybheoa .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>p-value</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span>"><strong>p-value</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left">Change in Blood Pressure</td> <td headers="stat_1" class="gt_row gt_center">4.9 (2.3)</td> <td headers="stat_2" class="gt_row gt_center">13.4 (5.7)</td> <td headers="p.value" class="gt_row gt_center"><0.001</td></tr> </tbody> <tfoot class="gt_footnotes"> <tr> <td class="gt_footnote" colspan="4"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span> Mean (SD)</td> </tr> <tr> <td class="gt_footnote" colspan="4"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span> Welch Two Sample t-test</td> </tr> </tfoot> </table> </div> **Conclusion:** Based on the p-value we reject the H0 and thus conclude there is a significant difference between the BP lowering effect of the New drug and Control --- # Is the BP lowering effect related to the age of the patient? ---- .pull-left[ **H0**: BP lowering effect is not related to age <div id="xfdsxgqlos" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#xfdsxgqlos table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #xfdsxgqlos thead, #xfdsxgqlos tbody, #xfdsxgqlos tfoot, #xfdsxgqlos tr, #xfdsxgqlos td, #xfdsxgqlos th { border-style: none; } #xfdsxgqlos p { margin: 0; padding: 0; } #xfdsxgqlos .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #xfdsxgqlos .gt_caption { padding-top: 4px; padding-bottom: 4px; } #xfdsxgqlos .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #xfdsxgqlos .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #xfdsxgqlos .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xfdsxgqlos .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xfdsxgqlos .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xfdsxgqlos .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #xfdsxgqlos .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #xfdsxgqlos .gt_column_spanner_outer:first-child { padding-left: 0; } #xfdsxgqlos .gt_column_spanner_outer:last-child { padding-right: 0; } #xfdsxgqlos .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #xfdsxgqlos .gt_spanner_row { border-bottom-style: hidden; } #xfdsxgqlos .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #xfdsxgqlos .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #xfdsxgqlos .gt_from_md > :first-child { margin-top: 0; } #xfdsxgqlos .gt_from_md > :last-child { margin-bottom: 0; } #xfdsxgqlos .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #xfdsxgqlos .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #xfdsxgqlos .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #xfdsxgqlos .gt_row_group_first td { border-top-width: 2px; } #xfdsxgqlos .gt_row_group_first th { border-top-width: 2px; } #xfdsxgqlos .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xfdsxgqlos .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #xfdsxgqlos .gt_first_summary_row.thick { border-top-width: 2px; } #xfdsxgqlos .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xfdsxgqlos .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xfdsxgqlos .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #xfdsxgqlos .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #xfdsxgqlos .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #xfdsxgqlos .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xfdsxgqlos .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xfdsxgqlos .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #xfdsxgqlos .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xfdsxgqlos .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #xfdsxgqlos .gt_left { text-align: left; } #xfdsxgqlos .gt_center { text-align: center; } #xfdsxgqlos .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #xfdsxgqlos .gt_font_normal { font-weight: normal; } #xfdsxgqlos .gt_font_bold { font-weight: bold; } #xfdsxgqlos .gt_font_italic { font-style: italic; } #xfdsxgqlos .gt_super { font-size: 65%; } #xfdsxgqlos .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #xfdsxgqlos .gt_asterisk { font-size: 100%; vertical-align: 0; } #xfdsxgqlos .gt_indent_1 { text-indent: 5px; } #xfdsxgqlos .gt_indent_2 { text-indent: 10px; } #xfdsxgqlos .gt_indent_3 { text-indent: 15px; } #xfdsxgqlos .gt_indent_4 { text-indent: 20px; } #xfdsxgqlos .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Beta</strong>"><strong>Beta</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>95% CI</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>p-value</strong>"><strong>p-value</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Age in years</td> <td headers="estimate" class="gt_row gt_center">0.08</td> <td headers="ci" class="gt_row gt_center">-0.19, 0.36</td> <td headers="p.value" class="gt_row gt_center">0.5</td></tr> </tbody> <tfoot class="gt_footnotes"> <tr> <td class="gt_footnote" colspan="4"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span> CI = Confidence Interval</td> </tr> </tfoot> </table> </div> **Conclusion**: BP lowering effect not significantly related to the age of the patient. ] .pull-right[ <!-- --> ] --- <div id="iieuwhijzg" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#iieuwhijzg table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #iieuwhijzg thead, #iieuwhijzg tbody, #iieuwhijzg tfoot, #iieuwhijzg tr, #iieuwhijzg td, #iieuwhijzg th { border-style: none; } #iieuwhijzg p { margin: 0; padding: 0; } #iieuwhijzg .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #iieuwhijzg .gt_caption { padding-top: 4px; padding-bottom: 4px; } #iieuwhijzg .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #iieuwhijzg .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #iieuwhijzg .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #iieuwhijzg .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #iieuwhijzg .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #iieuwhijzg .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #iieuwhijzg .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #iieuwhijzg .gt_column_spanner_outer:first-child { padding-left: 0; } #iieuwhijzg .gt_column_spanner_outer:last-child { padding-right: 0; } #iieuwhijzg .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #iieuwhijzg .gt_spanner_row { border-bottom-style: hidden; } #iieuwhijzg .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #iieuwhijzg .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #iieuwhijzg .gt_from_md > :first-child { margin-top: 0; } #iieuwhijzg .gt_from_md > :last-child { margin-bottom: 0; } #iieuwhijzg .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #iieuwhijzg .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #iieuwhijzg .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #iieuwhijzg .gt_row_group_first td { border-top-width: 2px; } #iieuwhijzg .gt_row_group_first th { border-top-width: 2px; } #iieuwhijzg .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #iieuwhijzg .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #iieuwhijzg .gt_first_summary_row.thick { border-top-width: 2px; } #iieuwhijzg .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #iieuwhijzg .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #iieuwhijzg .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #iieuwhijzg .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #iieuwhijzg .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #iieuwhijzg .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #iieuwhijzg .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #iieuwhijzg .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #iieuwhijzg .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #iieuwhijzg .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #iieuwhijzg .gt_left { text-align: left; } #iieuwhijzg .gt_center { text-align: center; } #iieuwhijzg .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #iieuwhijzg .gt_font_normal { font-weight: normal; } #iieuwhijzg .gt_font_bold { font-weight: bold; } #iieuwhijzg .gt_font_italic { font-style: italic; } #iieuwhijzg .gt_super { font-size: 65%; } #iieuwhijzg .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #iieuwhijzg .gt_asterisk { font-size: 100%; vertical-align: 0; } #iieuwhijzg .gt_indent_1 { text-indent: 5px; } #iieuwhijzg .gt_indent_2 { text-indent: 10px; } #iieuwhijzg .gt_indent_3 { text-indent: 15px; } #iieuwhijzg .gt_indent_4 { text-indent: 20px; } #iieuwhijzg .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <caption class='gt_caption'><strong>Table 6</strong>: Overall data outlook</caption> <thead> <tr class="gt_col_headings gt_spanner_row"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="2" colspan="1" scope="col" id="<strong>Characteristic</strong>"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="2" colspan="1" scope="col" id="<strong>Overall</strong>, N = 50<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>Overall</strong>, N = 50<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_center gt_columns_top_border gt_column_spanner_outer" rowspan="1" colspan="2" scope="colgroup" id="<strong>Drug</strong>"> <span class="gt_column_spanner"><strong>Drug</strong></span> </th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="2" colspan="1" scope="col" id="<strong>p-value</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span>"><strong>p-value</strong><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span></th> </tr> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>Old Drug</strong>, N = 22<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="<strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span>"><strong>New Drug</strong>, N = 28<span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Age in years</td> <td headers="stat_0" class="gt_row gt_center">61.5 (6.5)</td> <td headers="stat_1" class="gt_row gt_center">62.1 (6.6)</td> <td headers="stat_2" class="gt_row gt_center">61.0 (6.5)</td> <td headers="p.value" class="gt_row gt_center">0.6</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Sex</td> <td headers="stat_0" class="gt_row gt_center"></td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td> <td headers="p.value" class="gt_row gt_center">0.8</td></tr> <tr><td headers="label" class="gt_row gt_left"> Female</td> <td headers="stat_0" class="gt_row gt_center">26.0 (52.0%)</td> <td headers="stat_1" class="gt_row gt_center">11.0 (50.0%)</td> <td headers="stat_2" class="gt_row gt_center">15.0 (53.6%)</td> <td headers="p.value" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Male</td> <td headers="stat_0" class="gt_row gt_center">24.0 (48.0%)</td> <td headers="stat_1" class="gt_row gt_center">11.0 (50.0%)</td> <td headers="stat_2" class="gt_row gt_center">13.0 (46.4%)</td> <td headers="p.value" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Initial blood pressure (mmHg)</td> <td headers="stat_0" class="gt_row gt_center">98.3 (5.2)</td> <td headers="stat_1" class="gt_row gt_center">97.1 (3.6)</td> <td headers="stat_2" class="gt_row gt_center">99.2 (6.0)</td> <td headers="p.value" class="gt_row gt_center">0.13</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Blood Pressure after treatment</td> <td headers="stat_0" class="gt_row gt_center">88.6 (4.6)</td> <td headers="stat_1" class="gt_row gt_center">92.2 (3.3)</td> <td headers="stat_2" class="gt_row gt_center">85.8 (3.3)</td> <td headers="p.value" class="gt_row gt_center"><0.001</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Change in Blood Pressure</td> <td headers="stat_0" class="gt_row gt_center">9.7 (6.2)</td> <td headers="stat_1" class="gt_row gt_center">4.9 (2.3)</td> <td headers="stat_2" class="gt_row gt_center">13.4 (5.7)</td> <td headers="p.value" class="gt_row gt_center"><0.001</td></tr> <tr><td headers="label" class="gt_row gt_left" style="font-weight: bold;">Age Grouping</td> <td headers="stat_0" class="gt_row gt_center"></td> <td headers="stat_1" class="gt_row gt_center"></td> <td headers="stat_2" class="gt_row gt_center"></td> <td headers="p.value" class="gt_row gt_center">0.8</td></tr> <tr><td headers="label" class="gt_row gt_left"> Middle age</td> <td headers="stat_0" class="gt_row gt_center">17.0 (34.0%)</td> <td headers="stat_1" class="gt_row gt_center">7.0 (31.8%)</td> <td headers="stat_2" class="gt_row gt_center">10.0 (35.7%)</td> <td headers="p.value" class="gt_row gt_center"></td></tr> <tr><td headers="label" class="gt_row gt_left"> Elderly</td> <td headers="stat_0" class="gt_row gt_center">33.0 (66.0%)</td> <td headers="stat_1" class="gt_row gt_center">15.0 (68.2%)</td> <td headers="stat_2" class="gt_row gt_center">18.0 (64.3%)</td> <td headers="p.value" class="gt_row gt_center"></td></tr> </tbody> <tfoot class="gt_footnotes"> <tr> <td class="gt_footnote" colspan="5"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>1</sup></span> Mean (SD); n (%)</td> </tr> <tr> <td class="gt_footnote" colspan="5"><span class="gt_footnote_marks" style="white-space:nowrap;font-style:italic;font-weight:normal;"><sup>2</sup></span> Welch Two Sample t-test; Pearson’s Chi-squared test</td> </tr> </tfoot> </table> </div> --- # Summary... .pull-left[ ### Data Management - Database design - Data entry - Data validation - Data verification - Data cleaning - Data warehousing - Data transfer ] .pull-right[ ### Data Analysis - Statistical software - Data cleaning - Data analysis - Continuous variables - Categorical variables - Descriptive vrs. Inferential - Presentation of results - Tables - Figures ] --- class: inverse middle center <style> .bye{ font-size: 3em; font-weight: bold; /*font-style: italic;*/ color: white; } </style> .bye[ Thank you!!! ]